Research Data management
Research Data Management
KUHES Libraries provides a variety of training modules that cover the entire research data life cycle. These materials are aimed at researchers, library data specialists, research data managers, and discipline and functional experts working across the research data landscape
What is Research Data Management?
Research data management entails the active organization and maintenance of data throughout the research process, as well as appropriate data archiving at the end of the project. It is a continuous process that occurs throughout the data lifecycle.
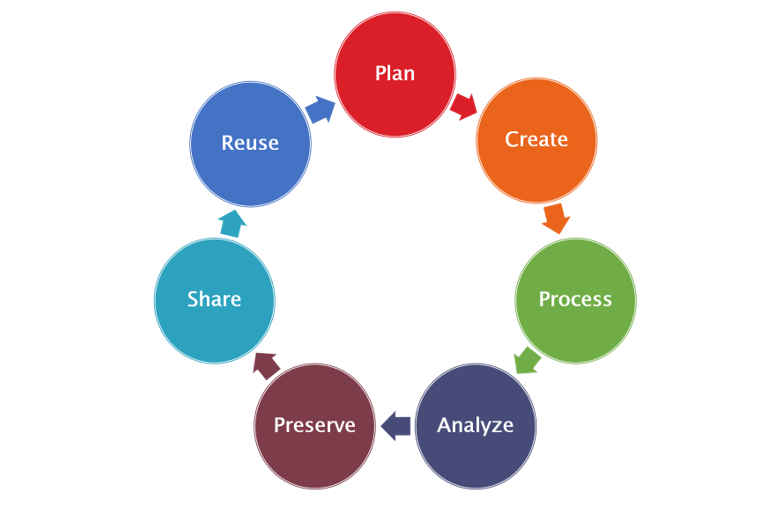
01.
Plan
Planning can include reviewing existing data sources, addressing informed consent, weighing costs, and developing a strategy.
02.
Create
Researchers generate data (through experimentation, observation, measurement, and simulation) and/or collect and organize third-party data and materials. Metadata and related materials are collected and generated.
03.
Process
Data is converted to digital format in accordance with quality assurance standards (transcribed, converted, digitized, curated). Data is checked, validated, cleaned, recoded, versioned, and anonymized as needed. All these processes are documented, and the data is described in accordance with the relevant discovery metadata standard.
04.
Analyze
Data is interpreted and analysed to generate research findings, publications, and intellectual outputs. The sources of the data are cited.
05.
Preserve
Data is saved in formats that adhere to curation best practices, user documents and discovery metadata are created, a digital identifier (i.e., DOI) is added, and data is linked to any published products; security and intellectual property are taken into account.
06.
Share
Access rights are confirmed (ethics and intellectual property considerations). The data, as well as user documentation and metadata, are made publicly available, for example, on a public domain server or in a controlled repository.
07.
Reuse
Reuse involves locating and obtaining potentially useful data, user documentation, and metadata. After any necessary data transformations have been completed, secondary analysis is performed. The transformation is documented, and the data sources are mentioned.